

Objectives of the project
The main objective of the system is to categorize word based on it use such as person, location, organization dates, quantities, numeric expressions, email and title (profession)
Problem statement
Named entity recognition is an important part of various natural language applications. It is employed in a preprocessing stage which extracts proper nouns required by many natural language applications to improve their performance. If we can extract needed information fast and efficiently. we can save a lot of time and resources.
Scope for the project
The scope of the project is to develop a java based system which can categorize a given set of text to a predefined category such as person, location, time, number, title and email.
Overview of Existing Systems
Notable NER platforms include:
- GATE
- OpenNLP
- SpaCy
These softwares are sophisticated and needs high expertise for using them. A non IT person can’t us them without training. Most of them lack user interface and most instructions are given in command line interface.
Target Work Force
This system to be developed can be used by wide range of audiences. From company recruiting employees to non IT worked to exact information from biodatas, transcripts, research papers, and all sorts of text documents. There is no need to be an expert in IT to use our system.
Methodology
Automatic Text Classification involves assigning a text document to a set of pre-defined classes automatically, using a machine learning technique. The classification is usually done on the basis of significant words or features extracted from the text document.
The system involves five phases (Fig. 1.)
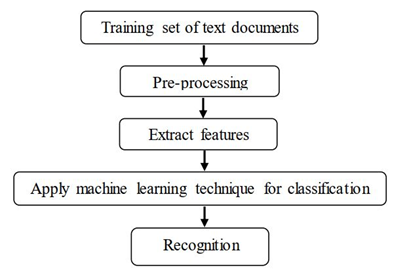
I. Training set of text documents
ii. Pre-processing
All the stop words and the code which is repeatedly coming are also removed. After this process there will be only plain text, the plain text has many English words, verbs, adjectives which are not of use. This Plain Text is processed and English Keywords are Removed using Database stored Keywords.
iii. Extract features
iv. Apply machine learning technique remaining text
The classifier will classify the featured word and will make a class in database with its information.
v. Recognition
Database
We will be using the data set of the stanfordcoreNLP developed by the university of stanford USA. We use this dataset because it contains large amount of data and it is open sourced and free to use Results
The output will be categorized into relevant component. The user can select the category and it show the output.
Technologies and tools
For this project we will be using the java libraries of stanford core nlp project. we are using dataset from same library too. we are going to develop the system using NetBeans IDE.
The versions are given below
- Stanford Named Entity Recognizer version 3.9.2
- NetBeans IDE Version 11
Future Modifications
We have an idea to develop a new layout that will enable us to add a text file, read it and categorize it. Further updating we can download the categorized as a spreadsheet.
References
- Incorporating Non-local Information into Information Extraction Systems by Gibbs SamplingJenny Rose Finkel, Trond Grenager, and Christopher Manning Computer Science Department
- https://en.wikipedia.org/wiki/Named-entity_recognition
- A survey of named entity recognition and classification
David Nadeau, Satoshi Sekine
National Research Council Canada / New York University
- A Survey on Deep Learning for Named Entity Recognition
Jing Li, Aixin Sun, Jianglei Han, and Chenliang Li
